Processing 3GiB of JSON in the browser in 2 seconds via WebAssembly
Starting with DuckDB
My first instinct was to try and import the files into DuckDB, a personal favorite tool for any kind of data crunching, especially when faced with really big JSON files. A quick throwaway query for all the gender prediction events looks a bit like this:
select *
from read_json('activity/analytics/events-2024-00000-of-00001.json',
format = 'newline_delimited',
auto_detect = true)
where (json->'predicted_gender') is not null;Not too bad! It loads all of the events in a second or two at most. It’s pretty easy to unpack this all into table columns, too:
select *
from read_json('activity/analytics/events-2024-00000-of-00001.json',
format = 'newline_delimited',
columns = {
predicted_gender: 'text',
prob_male: 'double',
prob_female: 'double',
prob_non_binary_gender_expansive: 'double',
day_pt: 'timestamp'})
where predicted_gender is not null;┌──────────────────┬────────────────────┬──────────────────────┬──────────────────────────────────┬─────────────────────┐
│ predicted_gender │ prob_male │ prob_female │ prob_non_binary_gender_expansive │ day_pt │
│ varchar │ double │ double │ double │ timestamp │
├──────────────────┼────────────────────┼──────────────────────┼──────────────────────────────────┼─────────────────────┤
│ male │ 0.8108658790588379 │ 0.11857519298791885 │ 0.07055895030498505 │ 2023-10-18 00:00:00 │
│ male │ 0.7923107147216797 │ 0.1035185381770134 │ 0.10417073965072632 │ 2023-12-13 00:00:00 │
│ male │ 0.6698217391967773 │ 0.14042726159095764 │ 0.18975096940994263 │ 2024-02-07 00:00:00 │
│ male │ 0.734815776348114 │ 0.08487804979085922 │ 0.1803061068058014 │ 2024-04-03 00:00:00 │
│ male │ 0.7945181131362915 │ 0.16594618558883667 │ 0.039535682648420334 │ 2023-01-11 00:00:00 │
│ male │ 0.7358677387237549 │ 0.1554252803325653 │ 0.10870702564716339 │ 2024-05-29 00:00:00 │
[...]
│ male │ 0.8582155108451843 │ 0.07383262366056442 │ 0.06795187294483185 │ 2023-11-08 00:00:00 │
│ male │ 0.6448849439620972 │ 0.19893291592597961 │ 0.1561821550130844 │ 2024-01-03 00:00:00 │
│ male │ 0.720182478427887 │ 0.09869085997343063 │ 0.1811266392469406 │ 2024-02-28 00:00:00 │
├──────────────────┴────────────────────┴──────────────────────┴──────────────────────────────────┴─────────────────────┤
│ 78 rows (40 shown) 5 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Perfect! Now, how to display it…
DuckDB vs WebAssembly
Initially, I had thought about making a native UI, but the number of cross-platform interactive chart libraries is apparently really low. Then I remembered reading about Observable and its support for DuckDB. Observable runs in the browser…could I make a client-side website that utilizes DuckDB? Turns out, DuckDB for WebAssembly exists! Perfect! I should just be able to load this up, pass an uploaded file to it, and be able to run my queries against the data. Thus, I went to work and came out with a prototype site that would do just that, along with some basic graphing support for the queries.
It took 17 seconds to run in Chromium (12 in Firefox). Oof.
As it turns out, there were a few factors that I failed to consider:
-
DuckDB on WebAssembly is single-threaded, whereas when I ran it natively, it was multi-threaded across my 10 cores. If I set it to only use one thread on the CLI, then the import time goes up to 5 seconds. There’s an experimental multi-threaded version of the WASM build, but I couldn’t get it to work, specifically with I/O support (see next point).
-
WebAssembly can’t directly perform I/O, delegating that all instead to a JS bridge. That results in a sizable amount of round trips to JS land and, more notably, leaves the I/O performance at the mercy of the browser’s buffer sizes (more on that later).
Also, for some reason the tables were using around 1GiB of RAM, probably because of some caches somewhere? But at this point I was losing heart in the idea of using DuckDB here.
Processing Ignoring 3GiB of data
This is where I must confess a grave sin:
The title is a lie. It’s filthy clickbait of the highest order. One does not simply process 3GiB of JSON in 2 seconds in a browser.
See, when playing around with the tables in DuckDB, I noticed something. Remember this snippet from the query output above?
78 rows (40 shown)
There were only 78 gender prediction events. What if I include the age ones?
select count(*)
from read_json('activity/analytics/events-2024-00000-of-00001.json',
format = 'newline_delimited',
auto_detect = true)
where (json->'predicted_gender') is not null or (json->'predicted_age') is not null;166
There’s…only 166 prediction events in total?? Out of over 2 million total events, I only care about 166??
Then why the hell is the code bothering to look at any of the others?
Time for a fresh approach! I figured could get significantly better performance by just
processing the JSON contents myself but skipping past all the lines that didn’t look
like they had one of the prediction events. After browsing through the file again, I
noticed that the model_version field is only present on the desired events, so that
string should be a good target for searching.
Here’s the crux of the code to do this (full version available
here with a
workaround for Bun’s lack of
TextDecoderStream):
let blob = await openAsBlob(process.argv[2])
// Anything past the final newline in a string chunk is part of an incomplete line and
// will get saved here.
let leftover = ''
let eventsFound = 0
let rd = blob.stream().pipeThrough(textDecoderStream()).getReader()
while (true) {
let { chunk, done } = await rd.read()
if (chunk === undefined) {
break
}
if (leftover.length !== 0) {
chunk = leftover + chunk
}
let offset = 0
while (true) {
let candidatePos = chunk.indexOf('model_version', offset)
if (candidatePos === -1) {
break
}
let lineEnd = chunk.indexOf('\n', candidatePos)
if (lineEnd === -1) {
break
}
let lineStart = chunk.lastIndexOf('\n', candidatePos)
lineStart = lineStart !== -1 ? lineStart + 1 : 0
let line = chunk.substring(lineStart, lineEnd)
let event = JSON.parse(line)
console.log(event)
eventsFound++
offset = lineEnd + 1
}
let nl = chunk.lastIndexOf('\n')
if (nl === -1) {
leftover = chunk
} else {
leftover = chunk.substring(nl + 1)
}
if (done) {
break
}
}
// Nothing should be left over past the final newline.
assert(leftover === '')
console.log({ eventsFound })Each loop, the code will read a string chunk and try to find an occurrence of
model_version. If it’s found, then the start and end of its line are located, and the
line is parsed. Once all instances of model_version are exhausted, any piece of an
incomplete line at the end of the string is saved into leftover to be combined with
the next string chunk read.
Let’s see how fast it can go:
$ hyperfine {node,bun}' loader.mjs events-2024-00000-of-00001.json'
Benchmark 1: node loader.mjs events-2024-00000-of-00001.json
Time (mean ± σ): 6.793 s ± 0.091 s [User: 5.426 s, System: 8.493 s]
Range (min … max): 6.647 s … 6.960 s 10 runs
Benchmark 2: bun loader.mjs events-2024-00000-of-00001.json
Time (mean ± σ): 2.182 s ± 0.023 s [User: 2.469 s, System: 0.437 s]
Range (min … max): 2.152 s … 2.221 s 10 runs
This is much better performance already!
I’m not entirely sure why Bun is so much faster here. Profiling the script in Chromium’s
devtools shows nearly 50% of the time in Node taken up just in TextDecoderStream and
related machinery. Additionally, Node returns chunks around 64KiB long (this is
foreshadowing for later in the article), compared to Bun’s 256KiB, so I suspect the
former spent more time just reading in the data. However, it’s hard to confirm all of
this, because I couldn’t figure out how to get any CPU profiling data from Bun’s
inspector, or if that’s even implemented.
Also yes, I am aware that Node has other file APIs, but in this case I used the blob APIs because that’s what the browser is using. Keep in mind that this is not intended to be a Node benchmark; rather, Node was just a convenient way to run it while testing.
Is this the fastest we can get, though? On every chunk read, we allocate a byte buffer to store the chunk, then decode that into a brand new string. That’s quite a bit of redundant allocating and decoding, especially given that most of these chunks are just going to be ignored.
But I can’t exactly just operate on byte arrays: JS APIs provide no way of searching
a byte buffer for a multi-byte sequence like model_version. If only there were a way
to use a language that provided this…
Back to WebAssembly we go
Instead of reading strings from the blob, could I read byte arrays and pass those over to Rust on WebAssembly to do the actual work? This would let me perform multi-byte searches and JSON parsing directly on the data without needing any decoding steps.
The invocation of Rust code isn’t free, however: you can’t directly pass a byte array to WASM without copying the data to its separate, isolated memory region. In order to avoid as many redundant copies as possible, I came up with a plan:
-
Read the data in using a BYOB (Bring Your Own Buffer) reader. This will allow the JS code to pre-allocate a single buffer and reuse it for multiple read operations.
-
Copy it directly to a pre-allocated buffer in the guest’s memory.
-
Call the Rust code with the number bytes filled in the buffer.
How do I bridge the JS and the Rust code, then? As far as I can tell, there are two primary solutions for this:
-
wasm-bindgen, a standalone Rust-specific bindings generator that relies on annotations left in the source code.
-
WebAssembly Component Model, a relatively new standard for defining "component" interfaces in an IDL (WIT), which is then processed by various other tools to generate the needed bindings on both the host and guest side.
At first, I went with wasm-bindgen, since it seemed to be the standard, more mature choice. However, I hit some…strange ergonomics issues with when it comes to returning structures. If you read the wasm-bindgen docs on exporting structs, you’ll notice that every struct exported from Rust is accessed via pointer on the JS side, i.e. the JS code has wrapper handles over a pointer allocated by Rust. This is pretty reasonable, but it gets extremely annoying if you want to return structs that act more as values types than rich objects. If I want to return two ints in a struct:
#[wasm_bindgen]
struct A {
pub x: i32,
pub y: i32,
}then the JS side has to deal with an entire heap-allocated wrapper object:
let a = somethingThatReturnsA()
try {
// Use a.x and a.y
} finally {
a.free()
}Now, technically I don’t need the manual free, because wasm-bindgen will use WeakRefs to let the garbage collector clean these up, but those come with some overhead which could pose a problem if a new one gets returned for every processed chunk.
Even outside of GC, the performance of returned structs gets much worse if the members are themselves structs, because those will be cloned every time you want to use them from JS:
#[wasm_bindgen(getter_with_clone)]
struct B {
pub inner_a: A,
}let b = somethingThatReturnsB()
try {
let a = b.inner_a // clones A
try {
// ...
} finally {
a.free()
}
} finally {
a.free()
}In my case, I wanted to return a struct containing more structs that contained several hundred numbers inside them. I don’t want to end up copying every layer of it multiple times!
Also notice the inner_a stays snake_case; in order to use camelCase names, you have to
rename every field by hand:
#[wasm_bindgen(getter_with_clone)]
struct B {
#[wasm_bindgen(js_name = innerA)]
pub inner_a: A,
}None of these are deal-breakers, of course; wasm-bindgen is a really great project that evidently has a huge userbase. Despite that, all of these little paper cuts added up to make me less interested in it and much more interested in…what is it again, something something component model?
Keep your WITs about you
Okay, how do I use this WebAssembly Component Model thing? First off, I needed a .wit file, the aforementioned cross-language IDL. This is how discordsona’s looks:
// I don't really get how package names work exactly, so I just went with "local" as
// the namespace like some examples used.
package local:discordsona;
interface loader {
// Records are POD value types.
record gender-predictions {
tally-female: u32,
tally-male: u32,
tally-non-binary-gender-expansive: u32,
day-pt: list<f64>,
prob-female: list<f64>,
prob-male: list<f64>,
prob-non-binary-gender-expansive: list<f64>,
}
record age-predictions {
tally-y13-y17: u32,
tally-y18-y24: u32,
tally-y25-y34: u32,
tally-y35-over: u32,
day-pt: list<f64>,
prob-y13-y17: list<f64>,
prob-y18-y24: list<f64>,
prob-y25-y34: list<f64>,
prob-y35-over: list<f64>,
}
record predictions {
age: age-predictions,
gender: gender-predictions,
}
record next-buffer {
ptr: u32,
size: u32,
}
// Resources are dynamically allocated objects with methods.
resource loader {
constructor(buffer-size: u32);
process-buffer: func(size: u32) -> result<next-buffer, string>;
// No built-in way of taking ownership from 'self' so a static method is needed. D:
finish: static func(self: loader) -> predictions;
}
}
// Idk what worlds are semantically, where is the name even used?
world w {
export loader;
}There are a bunch of interesting points here:
-
I like the distinction of records vs resources, and it perfectly covers my use case of returning simple structs that store their contents inline.
-
Resources can be borrowed or have their full ownership transferred, like in Rust. This is handy for the final
loadermethod, since the arrays inside can be moved out of the resource without any extra copies other than the standard JS <→ WASM ones. -
A lot of naming details are…not very well-documented? I read through a bunch of random issue threads on the WIT GitHub to try and figure out the significance of namespace and world names, and I mostly came away with the existence of https://wa.dev and very little knowledge of what "worlds" really mean. From what I can tell, their name isn’t even really used in any of the bindings generators? Of course, this is all very young, so I’d expect it to improve in the future.
Next, I needed a Rust wasm module that implements this interface. There are apparently two ways to do this:
-
wit-bindgen, a multi-language bindings generator. The Rust support involves invoking a procedural macro that parses a WIT file and generates the Rust binding code.
-
cargo-component, a Cargo command that implements a bunch of component functionality, including creating new projects and publishing them to an online registry. Bindings are generated via a subcommand that, when run externally, generates a .rs file.
I went with wit-bindgen, since avoiding an extra build step seemed convenient. I’m not
sure if this was the best choice in retrospect, though, since it seems to have weird
edge cases with rust-analyzer where I need to restart the it in order for changes to the
WIT file to participate in autocomplete. Additionally, I ended up often running cargo
expand to see the macro contents anyway, so a separate command might have been a bit
easier.
Rust-side
The code to implement the interface is pretty simple, requiring the user to implement
some traits corresponding to the interface and resources within. There’s a bit of
awkwardness in that the interfaces all require an immutable &self, so I ended up
splitting the logic out into a separate struct and just delegating everything to it
while wrapped in a RefCell:
struct LoaderImpl { /* [...] */ }
impl LoaderImpl {
fn new(buffer_size: u32) -> Self { /* [...] */ }
fn process_buffer(&mut self, size: u32) -> Result<NextBuffer, String> { /* [...] */ }
fn finish(self) -> Predictions { /* [...] */ }
}
struct CellWrapper<T>(RefCell<T>);
impl GuestLoader for CellWrapper<LoaderImpl> {
fn new(buffer_size: u32) -> Self {
Self(RefCell::new(LoaderImpl::new(buffer_size)))
}
fn finish(self_: Loader) -> Predictions {
self_.into_inner::<Self>().0.into_inner().finish()
}
delegate! {
to self.0.borrow_mut() {
fn process_buffer(&self, size: u32) -> Result<NextBuffer, String>;
}
}
}
struct World;
impl Guest for World {
type Loader = CellWrapper<LoaderImpl>;
}(The
actual code uses macros to implement new and finish, as a holdover from a previous version
where I had two different Loader implementations.)
As for the actual implementation, it’s conceptually pretty similar to the JS version:
struct LoaderImpl {
buffer: Vec<u8>,
leftover: usize,
finder: memmem::Finder<'static>,
json_buffers: simd_json::Buffers,
predictions: Predictions,
}The finder is used to find the model_version sequence from before:
impl LoaderImpl {
fn new(buffer_size: u32) -> Self {
Self {
buffer: vec![0; buffer_size as usize],
leftover: 0,
finder: memmem::Finder::new("model_version"),
// is buffer_size a good size for this?
json_buffers: simd_json::Buffers::new(buffer_size as usize),
predictions: Default::default(),
}
}
/* [...] */
}Actually processing the buffer should look familiar:
impl LoaderImpl {
/* [...] */
fn process_buffer(&mut self, size: u32) -> Result<NextBuffer, String> {
let size = size as usize;
if self.leftover + size > self.buffer.len() {
return Err(format!(
"{} + {} > {}",
self.leftover,
size,
self.buffer.len()
));
}
let buffer = &mut self.buffer[..self.leftover + size];
let mut remaining = &mut buffer[..];
while !remaining.is_empty() {
let Some(candidate) = self.finder.find(remaining) else {
break;
};
let Some(line_end) =
memchr(b'\n', &remaining[candidate..]).map(|n| n + candidate)
else {
break;
};
let line_start = memrchr(b'\n', &remaining[..candidate]).map_or(0, |i| i + 1);
if let Ok(event) = simd_json::serde::from_slice_with_buffers::<Event>(
&mut remaining[line_start..line_end],
&mut self.json_buffers,
) {
/* [...actually fill in self.predictions from the event...] */
}
remaining = &mut remaining[line_end + 1..];
}
if let Some(last_newline) = memrchr(b'\n', buffer) {
let last_line_start = last_newline + 1;
self.leftover = buffer.len() - last_line_start;
if self.leftover > 0 {
buffer.copy_within(last_line_start.., 0);
}
} else {
if buffer.len() == self.buffer.len() {
self.buffer.resize(self.buffer.len() * 2, 0);
}
self.leftover += size;
}
let next_buffer = &mut self.buffer[self.leftover..];
Ok(NextBuffer {
ptr: next_buffer.as_mut_ptr() as u32,
size: next_buffer.len() as u32,
})
}
/* [...] */
}Each loop, as many lines as can be are processed from the buffer, and anything left over gets moved to the front, returning a pointer to what remains for the JS to fill. The main magic is the use of the excellent SIMD-optimized memchr crate for doing the actual searches; this is where the majority of the time tends to be spent, so optimizing that is pretty important. simd_json’s use is a "bit" less important, since it’s only being called a few hundred times in total, but using it gives me warm fuzzy feelings.
Since the buffer size is fixed now, there’s some extra logic to handle growing it if a single line is too long. I don’t expect this to really happen in practice, but it’s a useful extra safety net.
JS-side
That all takes care of the Rust side. For the JS host,
jco generates bindings for a component and also
wraps a bunch of related component commands in one place. At a surface level, it’s
pretty easy to use: you run jco new to convert a compiled WASM module to a component
and jco transpile to create the JavaScript wrapper code and TypeScript declarations.
In practice, there were a few…quirks? with the generated JS:
-
It doesn’t give access to the underlying memory, which I need to be able to fill the buffers.
-
The wasm filename is hardcoded, which isn’t that much of a fundamental issue…but I’d like to be able to switch the file out between dev & prod builds so that the latter can be stripped, which drops the file size down from ~1.8MiB → ~190KiB. This can technically be accomplished as-is by just copying the entire output file tree, stripping the version in the copy, and using dynamic imports in my own JS to choose which version to use, but that gets annoying quickly.
To fix this, I ended up patching the generated JS from my build script:
let componentCore = 'component.core.wasm'
let componentCoreOpt = 'component.core.opt.wasm'
// [...]
await appendFile(`${out}/component.d.ts`, ';export const memory0: WebAssembly.Memory;')
await modifyFile(`${out}/component.js`, (contents) => {
let edited = contents.replace(
`new URL('./${componentCore}', import.meta.url)`,
(x) =>
`(import.meta.env.DEV ? ${x} : ${x.replace(componentCore, componentCoreOpt)})`,
)
assert(contents !== edited)
return edited + ';export {memory0};'
})
await $`../node_modules/binaryen/bin/wasm-opt \
--strip-debug -o ${out}/${componentCoreOpt} ${out}/${componentCore}`The middle statement in particular will perform this replacement:
// original:
new URL('./component.core.wasm')
// changed:
(import.meta.env.DEV
? new URL('./component.core.wasm')
: new URL('./component.core.opt.wasm'))new URL(import.meta.env.DEV ? …) but that didn’t exactly work.
Well, it "worked" in that the correct component file was included in the dist, but it
didn’t work in that Vite completely failed te rewrite the URL to match the final
filename. It’s a bit bizarre to me that it worked in one place but not another, but at
least fixing it was simple.
The invoking JS code again retains the rough structure of the previous version (this is trimmed down to remove some performance measures and progress reporting):
let buffer = rd instanceof ReadableStreamDefaultReader
? null
: new ArrayBuffer(bufferSize)
let mem = new Uint8Array(impl.memory0.buffer)
let loader = new impl.loader.Loader(buffer.byteLength)
let { ptr: targetPtr, size: targetSize } = loader.processBuffer(0)
while (true) {
if (buffer !== null && targetSize > buffer.byteLength) {
buffer = new ArrayBuffer(targetSize)
}
let { value, done } = rd instanceof ReadableStreamDefaultReader
? await rd.read()
: await rd.read(new Uint8Array(buffer!, 0, targetSize))
if (value === undefined) {
break
}
let offset = 0
while (offset < value.length) {
let remaining = value.length - offset
let toSend = offset === 0 && remaining <= targetSize
? value
: value.slice(offset, Math.min(targetSize, remaining))
if (mem.byteLength === 0) {
mem = new Uint8Array(impl.memory0.buffer)
}
mem.set(toSend, targetPtr)
;({ ptr: targetPtr, size: targetSize } = loader.processBuffer(toSend.byteLength))
offset += toSend.byteLength
}
totalProcessed += value.byteLength
if (done) {
break
}
buffer = value.buffer
}As expec—wait, what are the instanceof checks for? Perhaps unsurprisingly, BYOB reader
support is a bit…lacking in some browsers, and by "lacking" I mean it
literally doesn’t exist:
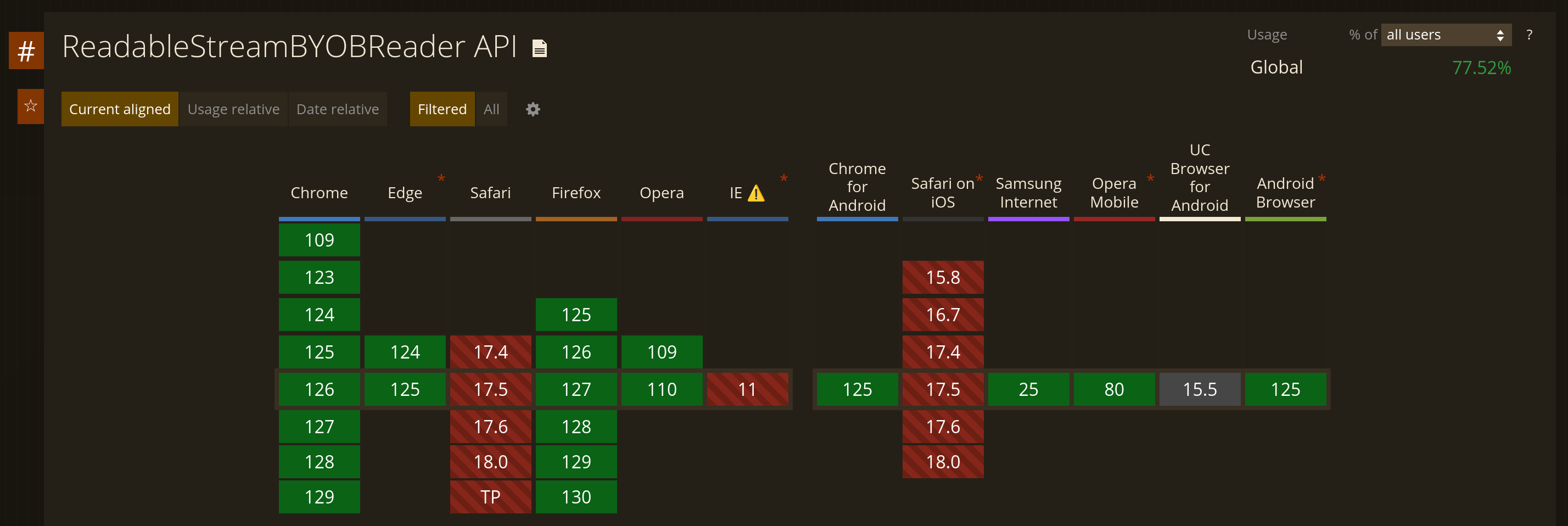
WebKit, why 😭.
Thus, the caller needs to conditionally enable the use of BYOB readers:
try {
byobReader = stream.getReader({ mode: 'byob' })
} catch (ex) {
if (!(ex instanceof TypeError)) {
throw ex
}
}
// [...]
return await loadFromReader(
byobReader ?? stream.getReader(),
progress,
options,
);This is also the reason for:
while (offset < value.length) {
let remaining = value.length - offset
let toSend = offset === 0 && remaining <= targetSize
? value
: value.slice(offset, Math.min(targetSize, remaining))
// [...]
offset += toSend.byteLength
}If a BYOB reader can’t be used, then there’s no way to constrain the max size of the chunk to fit the buffer, so the code might have to split it into multiple pieces.
There’s also this weird block to handle
recreating the Uint8Array if the underlying memory was resized:
if (mem.byteLength === 0) {
mem = new Uint8Array(impl.memory0.buffer)
}With all that out of the way, the core logic is simple:
-
Fill as much of the buffer as possible.
-
Call the WebAssembly code with the amount filled.
-
Update the buffer pointer and size with the resulting values.
The results
I measured the number of seconds it took to perform each of five runs on clean profiles of three browsers:
-
Chromium 126, from Flathub.
-
Firefox 129.0a1, from the unofficial nightly Flatpak repo.
-
GNOME Web 46.1, from Flathub.
All of these are running on Fedora 39 on a MacBook Pro with M1 Max.
| # | Chromium | Firefox | Web |
|---|---|---|---|
1 |
1.61 |
3.24 |
1.12 |
2 |
2.25 |
3.16 |
1.20 |
3 |
2.80 |
3.32 |
1.23 |
4 |
2.30 |
3.15 |
1.15 |
5 |
1.75 |
3.22 |
1.15 |
These are some…interesting results:
-
I need to apologize for complaining about WebKit earlier, because it managed to consistently beat every other browser, despite being unable to use the BYOB reader.
-
Chromium is generally the second-fastest, but the results are a bit inconsistent, with some runs taking a full second more than others. (I suspect that this might be due to the way it actually reads the blob data.)
-
Firefox is consistently in last place.
In order to try to drill into this a bit more, I also augmented the code to take some
rough estimates of how much time it taken by WebAssembly code and the bindings, taken by
comparing performance.now() before and after each call into the loader. If I use those
values, suddenly the results change quite a bit:
| # | Chromium | Firefox | Web |
|---|---|---|---|
1 |
0.91 |
1.36 |
0.74 |
2 |
1.04 |
1.38 |
0.74 |
3 |
1.24 |
1.26 |
0.77 |
4 |
1.07 |
1.24 |
0.71 |
5 |
0.96 |
1.21 |
0.74 |
All browsers seem to actually spend a significant amount of time outside of the WebAssembly code. Although Firefox is still the slowest, it particularly seems to spend over half of its time elsewhere.
I’m not entirely sure what’s going on here, but I did discover something that I think could be part of the problem: the max buffer size. Every browser tested seems to have a limit for how many bytes it will read every time, even for a user-provided buffer. I updated the code to log the buffer sizes, and the values I observed were:
-
Chromium: 2MiB.
-
Firefox: 64KiB.
-
GNOME Web: 512KiB.
Firefox’s buffers are absolutely microscopic compared to either other engine, which I suspect is part of the reason behind its poor showing. That being said, if I change the BYOB buffer size in Chromium to 64KiB, it still exhibits superior performance, but its internal buffers are still 2MiB large which could be impacting the measurements.
Amusingly, I also found out that, if I don’t use BYOB readers on Chromium and Firefox, they both regress even further, by ~0.5s on average. Again, kudos WebKit.
What about the rest of the site?
Business logic isn’t exactly enough for a functioning website, since you still need, uhh, the website. The tools I chose for this were:
-
Vue 3: I haven’t seriously used Vue since the 2.x days (due to reasons completely unrelated to Vue itself). It’s come along really nicely since then; I’m particularly fond of how the compisition API plays along with TypeScript.
-
Element Plus for the UI: Well, since the 2.x days, it would seem that the UI framework scene has also changed by quite a bit. I fell in love with the look of Element Plus pretty quickly, and I haven’t had any major issues with it other than some lack of flexibility with the animations for the progress components.
-
Chart.js: At first I tried out some other chart libraries like Observable Plot and ApexCharts, but nothing really got the mix between being robust and supporting interactivity like Chart.js did. I have my qualms (the trial-and-error of setting up
ChartJS.registeris pretty annoying), but in the end it worked out quite well. -
Vite: This is actually one of my favorite tools from this list. I do not miss dealing with Webpack and the horrifying ejected configurations at all.
-
Comlink: Robust web worker communication can be tricky, but this takes out almost all of the pain by creating RPC wrappers for the worker’s interface.
-
Bun: I was a bit skeptical of this project for a while, but honestly, I’ve had an enjoyable experience so far. There are certainly some…rough edges (Vite’s dev server will sometimes segfault after printing a bunch of inotify-errors lolsob), but for development purposes, I’ll happily trade some sanity off in exchange for really fast package management and script startup times. Also,
Bun.$is legitimately brilliant, and I wish more language runtimes had built-in ways to conveniently run shell commands with proper integrated quoting support.
Well, that was an adventure
This is actually the first time I’ve used WebAssembly in the browser, and I think it went pretty well. In the end, I did manage to digest the data reasonably quickly across every major browser, and the final website does look pretty:
Mission accomplished!
Appendix: How do browsers read blobs?
When I started suspecting I/O performance issues, I tried to examine the source code of the three browsing engines tested to find out where exactly the buffer sizes come from.
Firefox
Over in StreamBlobImpl,
notice the value of kBaseSegmentSize as 64KiB:
static already_AddRefed<nsICloneableInputStream> EnsureCloneableStream(
nsIInputStream* aInputStream, uint64_t aLength) {
// [...]
// If the stream we're copying is known to be small, specify the size of the
// pipe's segments precisely to limit wasted space. An extra byte above length
// is included to avoid allocating an extra segment immediately before reading
// EOF from the source stream. Otherwise, allocate 64k buffers rather than
// the default of 4k buffers to reduce segment counts for very large payloads.
static constexpr uint32_t kBaseSegmentSize = 64 * 1024;
uint32_t segmentSize = kBaseSegmentSize;
if (aLength + 1 <= kBaseSegmentSize * 4) {
segmentSize = aLength + 1;
}
// NOTE: We specify unlimited segments to eagerly build a complete copy of the
// source stream locally without waiting for the blob to be consumed.
nsCOMPtr<nsIAsyncInputStream> reader;
nsCOMPtr<nsIAsyncOutputStream> writer;
NS_NewPipe2(getter_AddRefs(reader), getter_AddRefs(writer), true, true,
segmentSize, UINT32_MAX);
// [...]
cloneable = do_QueryInterface(reader);
MOZ_ASSERT(cloneable && cloneable->GetCloneable());
return cloneable.forget();
}
// [...]
/* static */
already_AddRefed<StreamBlobImpl> StreamBlobImpl::Create(
already_AddRefed<nsIInputStream> aInputStream, const nsAString& aName,
const nsAString& aContentType, int64_t aLastModifiedDate, uint64_t aLength,
const nsAString& aBlobImplType) {
nsCOMPtr<nsIInputStream> inputStream = std::move(aInputStream);
nsCOMPtr<nsICloneableInputStream> cloneable =
EnsureCloneableStream(inputStream, aLength);
RefPtr<StreamBlobImpl> blobImplStream =
new StreamBlobImpl(cloneable.forget(), aName, aContentType,
aLastModifiedDate, aLength, aBlobImplType);
blobImplStream->MaybeRegisterMemoryReporter();
return blobImplStream.forget();
}Chromium
Reading blobs is done by a BlobBytesConsumer which reads the data in over a Mojo stream:
BytesConsumer::Result BlobBytesConsumer::BeginRead(const char** buffer,
size_t* available) {
if (!nested_consumer_) {
if (!blob_data_handle_)
return Result::kDone;
// Create a DataPipe to transport the data from the blob.
MojoCreateDataPipeOptions options;
options.struct_size = sizeof(MojoCreateDataPipeOptions);
options.flags = MOJO_CREATE_DATA_PIPE_FLAG_NONE;
options.element_num_bytes = 1;
options.capacity_num_bytes =
blink::BlobUtils::GetDataPipeCapacity(blob_data_handle_->size());
// [...]
}
return nested_consumer_->BeginRead(buffer, available);
}(I suspect that the IPC here might be why Chromium’s performance is so inconsistent, but I haven’t profiled it all.)
That GetDataPipeCapacity function seems interesting; what does it do exactly?
// The 2MB limit was selected via a finch trial.
constexpr int kBlobDefaultDataPipeCapacity = 2 * 1024 * 1024;
constexpr base::FeatureParam<int> kBlobDataPipeCapacity{
&kBlobDataPipeTuningFeature, "capacity_bytes",
kBlobDefaultDataPipeCapacity};
// [...]
// static
uint32_t BlobUtils::GetDataPipeCapacity(uint64_t target_blob_size) {
static_assert(kUnknownSize > kBlobDefaultDataPipeCapacity,
"The unknown size constant must be greater than our capacity.");
uint32_t result =
std::min(base::saturated_cast<uint32_t>(target_blob_size),
base::saturated_cast<uint32_t>(kBlobDataPipeCapacity.Get()));
return std::max(result,
base::saturated_cast<uint32_t>(kBlobMinDataPipeCapacity));
}Found the 2MiB!
WebKit
BlobResourceHandle has a
nicely named constant
that gets used later in the file:
static const unsigned bufferSize = 512 * 1024;
// [...]
client()->didReceiveResponseAsync(this, WTFMove(response), [this, protectedThis = Ref { *this }] {
m_buffer.resize(bufferSize);
readAsync();
});